.png)
正则表达式的基本使用
编辑该篇主要是21年时给大二同学讲学的内容,今整理电脑,发现了当时的PPT及讲义,故记录于此,并且加以完善。
正则表达式
为什么要学习正则表达式?
在日常生活中,我们常常会用到检索和替换的功能,若把一个word里的“张三”替换成“李四”,这不是难题,不过是ctrl+H罢了。在基于语料库的文本研究中,我们常常会遇到一些更复杂的需求,例如
- 统计语料库里面出现的句子数目?
- 统计语料库里面出现的所有年份?
- 统计文章中出现的汉字数目?
- 找到文章中包含”把……了”模式的句子的数目?
如果依靠人工逐个查询,随着语料库规模的扩大,将无从下手。如何快速实现上述功能呢?我们就需要正则表达式。
简介
正则表达式(Regular Expression),通常简称为正则或正则表达式,是一种强大的文本处理工具,用于在字符串中进行模式匹配和搜索操作。正则表达式由一系列字符和特殊符号组成,其定义了一个检索模式,用于匹配字符串中的文本。正则表达式在很多编程语言和应用程序中都得到广泛应用。
正则表达式(Regular Expression,简写为regex、regexp或RE),是计算机科学的一个概念。正则表达式使用单个字符串来描述、匹配一系列符合某个句法规则的字符串。在很多文本编辑器里,正则表达式通常被用来检索、替换那些符合某个模式的文本。例如:
\d+: 表示任意长度的数字串: 1, 10, 11111, 23456789[一-龥]:表示任意的汉字^我:以“我”字开始的行
正则表达式的特点:
- 灵活性、逻辑性和功能性非常强;
- 可以迅速地用极简单的方式达到字符串的复杂控制。
- 对于刚接触的人来说,比较晦涩难懂。
为什么[一-龥]表示所有的汉字?
- 在unicode编码中,\u4e00-\u9fa5是用来判断是不是中文的一个条件,期间的汉字总共有29001个。\u4e00对应“一”,\u9fa5对应“龥”。


正则表达式构成元素
1. 基本字符及元字符:
- a, b, c, d, …, z (26个小写字母)
- A,B,C,D,…,Z (26个大写字母)
- 0,1,2,3,…..,9 (10个数字)
- 一,二,三,….,龥 (所有的汉字)
- ~,!,@,#,$,%,… (大部分图形字符)
以上是基本字符,其特点是“所见即所得”,即在文章中直接匹配基本字符。和前文中提到的“张三”替换“王五”一样,是最简单的检索操作。
所谓元字符,就是一些有特殊含义的字符,也叫特殊字符,它们不表示原先的图形符号的含义,具有了新的含义。常用的元符号有: \ [] { } ( ) + * ? ^ $ .等。他们的含义在后文中会说明,但在需要提前说明的是
2.转义字符
(1)某些基本字符(主要是英文字母)会和转义符号\结合变成别的符号。
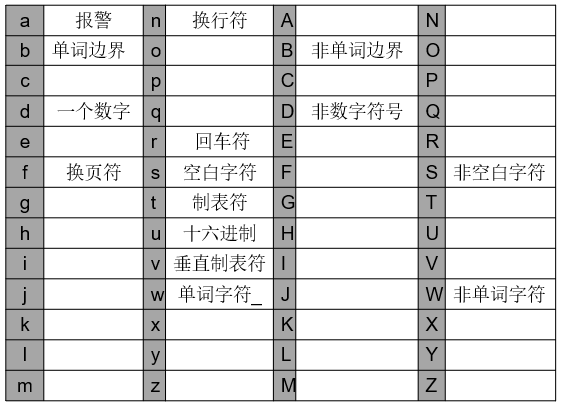
\b: 不匹配任何字符,只匹配单词边界。
\B: 匹配任何字符,除了单词边界\d:匹配任何数字字符,
\D:匹配任何非数字字符,等效于[^0-9]。\s: 空白字符(空格,TAB, 换行,回车符)
\S: 匹配任何字符,除了空白字符。\w:匹配任何单词字符(字母、数字、下划线),等效于[a-zA-Z0-9_]。
\W:匹配任何非单词字符。
(2)转义符号的另外一个作用是将元符号还原为基本符号。如果我就想检索元符号本身应该怎么办呢?比如就想检索(,此时是不能直接搜索(的,而要在前面加上\,即\(。
在元符号前加\,便可以将这个元符号还原为本身的图形符号进行检索。检索\本身的表达是就是\\。
3. 字符类
某些相同性质字符共同构成字符类,可以用专用符号[ ]表示。
[abc]表示匹配一个字符,该字符是a、b 或 c[a-z]表示匹配一个字符,该字符介于a 到 z之间,也就是所有的小写字母[0-9]表示匹配一个数字[一-龥]表示匹配一个汉字字符[a-zA-Z]表示匹配英文字母
4.限定符
限定符用来指定正则表达式的一个匹配模式必须要出现多少次才能满足匹配,可以叫做数量词。


例如:
[一-龥]{50}匹配由50个汉字构成的字符串[a-zA-Z]{5,20}匹配由英文字母构成的单词串,长度介于5-20之间
5.定位符
\b:匹配一个单词边界,不匹配任何字符^:匹配字符串开始的地方,不匹配任何字符$: 匹配字符串结束的地方,不匹配任何字符
将该文本:我去!这两个年轻人不讲武德,来骗!来偷袭,我六十九岁的老同志。这好吗?这不好!我……
分别匹配:我 ^我 我$ \b我\b
会发生什么呢?请你先设想一下,然后通过下面的网站检验。
正则表达式在线测试
6.逻辑运算符
-
与:“与”是正则表达式中最普通的逻辑关系。一般来说,如果正则表达式中的元素没有任何量词cat,就表示“这里必须依次出现c、a、t,3个字符”。
-
非
^:在前文中,我们说到^匹配字符串开始的地方,这种定位符的意义限于在整个正则表达式的开头。
但是,如果在字符类内部:当 ^ 出现在字符类(用方括号 [] 括起来的字符集合)的开头时,它表示取反或排除的含义。例如,[^abc] 表示匹配任何字符,只要它不是 "a"、"b" 或 "c" 中的一个。这用于指定一个字符不应该出现在匹配中的情况。不能出现某个字符,用排除型字符组[^]就可以解决。
比如说我们想提取人物的话语(引号里的话),其长度不确定,所以用*来限定,所以整个表达式就是:[^“”]*这个正则表达式
[^“”]*表示的是一个匹配任意数量(包括零个)不包含中文引号“”的字符的模式。[^“”]:使用了方括号[]来定义一个字符类,它表示匹配不包含在字符类内的任何字符,其中包括了中文引号“”。*:表示前面的字符类可以重复零次或多次。
-
或
|:在正则表达式中,竖线|表示逻辑上的“或”操作符,用于匹配多个模式中的任意一个。具体来说,它可以用于将多个模式组合在一起,以便匹配其中之一。例如,如果你有一个正则表达式 (cat|dog),它将匹配包含单词 "cat" 或 "dog" 的文本。这表示它会查找文本中的 "cat" 或 "dog",并在找到其中一个时返回匹配。
需要注意的是,字符具有高于替换运算符的优先级,使得"m|food"匹配到的是"m"或"food"而并非“mood”或“food”。若要匹配"mood"或"food",需要使用
()括号创建子表达式,从而产生"(m|f)ood"。
7. 分组和捕获
正则表达式中的分组和捕获允许用户对模式进行分组,并可以从匹配的文本中提取或引用这些分组。分组通常使用圆括号 ()来定义。每一捕获组按照括号出现的顺序进行编号。
例如:如,在正则表达式ABC中加入括号 (A)(B(C)) 中,存在三个这样的组:
1. (A)
2. (B(C))
3. (C)
每个组在替换时可以用\1,\2,\3代替。
假设你有一个文本文件包含日期信息,日期格式是 "YYYY-MM-DD",但你想将日期格式改为 "DD/MM/YYYY"。你可以使用正则表达式分组和捕获来实现这个目标。
原文件如下:
Date: 2023-09-21
Date: 2023-09-22
Date: 2023-09-23
正则表达式匹配:
(\d{4})-(\d{2})-(\d{2})
替换为:
\3/\2/\1
运行后:
Date: 21/09/2023
Date: 22/09/2023
Date: 23/09/2023
- 0
- 0
-
分享