.png)
实验语音学常用软件入门•Praat声调格局
编辑本文“操作步骤”部分内容基于软件“Praat汉化修改版4.5”(Paul Boersma & David weenink 开发,贝先明和向柠 修改)相关课程的教学内容,其余内容为笔者构思、撰写与引用。本文仅用于个人学习交流目的,不可用于商业用途。如有任何侵权行为,或本文中的任何内容侵犯了原软件作者的版权,请在第一时间告知作者,我将立即采取措施解决。本文采用CC BY-NC-SA 4.0许可协议。你可自由分享、演绎,但需署名、非商业使用,并以相同许可协议分享演绎作品。
理论基础
基频与声调格局
稍微涉猎语音学的读者都知道,我们所感受到的声调最相关的物理量是基频。一般认为,某个声调基频曲线即可表示该声调的音高变化。所以,我们的首要目标是想画出某个调的基频曲线。此时,我们便需要找合适的发音人去发某个字的音,比如阴平字“八”,提取各个点的基频(Hz)值,将其连线,便可以得到一条阴平的曲线。
但此时我们会发现一个问题,我们现在无法给这个调取一个五度调值(即使我们都知道阴平调是55)。因为我们不知道纵坐标的范围,这条单独的阴平曲线,我们只能模糊地描述其为“平调”,说其调值是“55”“33”“22”是没有意义的,因为并没有合适的参考系。我们必须同时画出其他几个调的曲线,确定相对变化的音高范围,才能画出这个语言正确的声调格局,正确地描述调值。
声调格局就是由一种语言或方言中的全部单字调所构成的格局。广义的声调格局应该包括两字组及多字组连读的声调表现,那就成为声调的动态分析。单字调的声调格局是静态的分析,是声调研究的基础形式,是考察各种声调变化的起始点。
——石锋, 冉启斌, 王萍, 2010. 论语音格局[J]. 南开语言学刊(01): 1-14+185.
归一化
在画出了一个发音人的声调的基频曲线后,并不代表大功告成了。即使对于同一个发音人,发同一个声调的各个例字,也会产生很多差异。一个朴素的想法是:取均值不就好了。但事实是,简单的均值处理并不会表现出声调曲线的真实情况。
上面说的是同一发人之内的差异,而多个发音人的差异就更容易理解了。因为样本量太少,数据可能与整体存在偏差,也即一个人的语音情况不一定能代表这个语言的普遍情况,而我们的研究目的一般是调查某一行政区域(县村乡)的语音情况,所以要从两个方面出发,一是发音人要足够典型,二是发音样本要尽量多。如果要结合某些新算法和新模型(如GCA等),则需要更多的发音样本。一般认为,“方言老男”所说的当地话是最正宗的,调查其他年龄段和性别便为语音演变和社会语言学的研究提供了语料基础。
每个调查点均需要调查老年男性、青年男性、老年女性、青年女性等 4 名汉语方言发音人,分别用“方言老男”、“方言青男”、“方言老女”、“方言青女”来指称,又简称为“老男”、“青男”、“老女”、“青女”。
方言发音人条件:
(1)老年发音人调查时年龄在 55-65岁之间,青年发音人调查时年龄在25-35岁间,老年发音人和青年发音人(特别是“方言老男”和“方言青男”)之间的年龄隔应不小于25岁。
(2)必须在当地出生和长大,家庭语言环境单纯(父母、配偶均是当地人),未在外地长住,能说地道的当地方言。
(3)老年发音人具有小学或中学文化程度(一般不宜选择大专及其以上文化程度的),青年发音人不作限制。
(4)具有较强的思维能力、反应能力和语言表达能力,发音洪亮清晰。
如果选择发音人有困难,限制条件可适当放宽。——《中国语言资源调查手册·汉语方言》
在收集到不同发音人的大量语料后,又出现了一个问题:每个人的调域不同,有高有低。假设一个极端情况,一个低沉男声的最高音可能低于一个尖锐女声最低音。所以我们需要进行归一化。
一个语言信号的物理性质表现形式是无限多的 。 归一化的主要目的是消减人际随机差异 , 提取恒定参数 , 在语际变异中找到共性 , 从而使得人际比较和语际比较的研究成为可能
——朱晓农. 基频归一化——如何处理声调的随机差异?[J]. 语言科学, 2004(02): 3-19.
现在常见的归一化方法有z-score法、T值法、对数z-core法、半音法等。究竟哪种归一化方法最好,学界尚存争论,依笔者所观,其中国际使用最广的是z-score方法,朱晓农老师的对数Z-score(LZ)方法是对其优化。为降低初学者难度,本教程采用praat汉化修改版4.5(Paul Boersma & David weenink (2020))开发,贝先明和向柠(2020)修改)进行相关分析,由于praat汉化修改版内置了T值方法,简化了大量操作步骤,故本文使用T值法进行演示。研究者也可以使用基频数据进行其他归一化方法的数值转化。声调分析中,基频是最重要的数据,是各类归一化方法的数据基础。
praat原版为全英文界面,采集数据的大量脚本需要研究者自行寻找或编写代码,对于很多研究者来说无疑提高了门槛。本系列不使用原版Praat进行语音分析,而使用praat汉化修改版4.5,此版本在praat原版功能的基础上,添加了众多汉语语音调查的实用功能,将过去较为复杂的提取和计算过程内置到软件里,降低了praat软件的使用难度,使研究者可以轻松获得目标数据。
实验材料与工具
- 录音材料:每个声调最好选取 20-30 个例字(词)。在双字调实验中,则需要四声分别搭配,共计 16 种组合,并选取不同词组多次测量。
- Praat汉化修改版4.5(Paul Boersma & David weenink)开发,贝先明和向柠(2020)修改)
操作步骤-单字调分析
录入/读取音频
-
打开 praat 软件,点击
打开→从文件读入…,将声调文件读入(可一次读入多个文件)。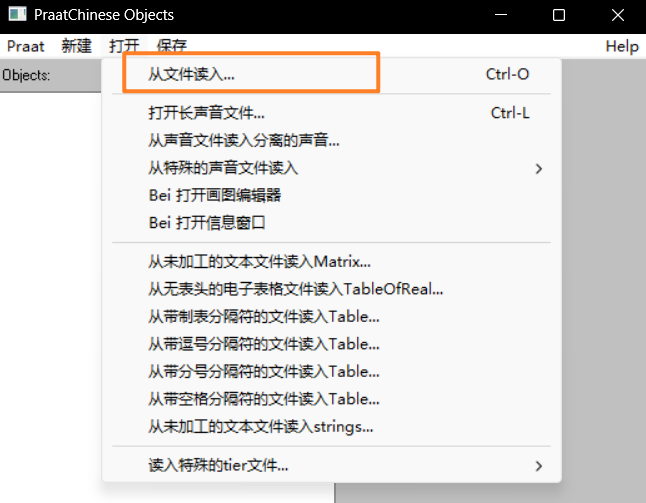
-
选中某个需要提取基频的文件,点击右侧
查看与编辑,之后会弹出语图页面。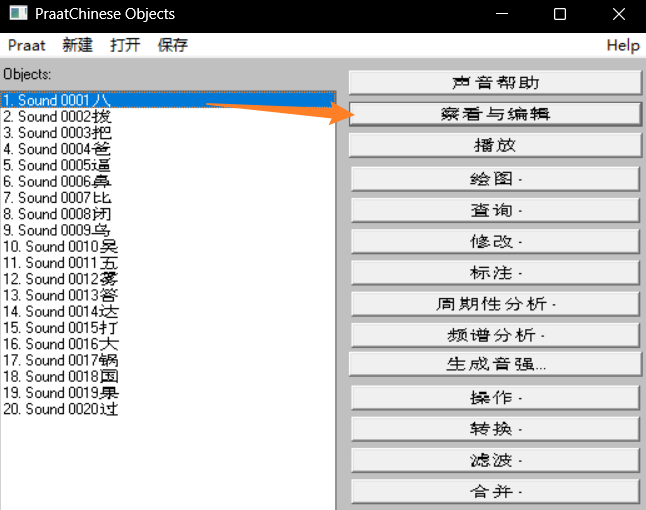
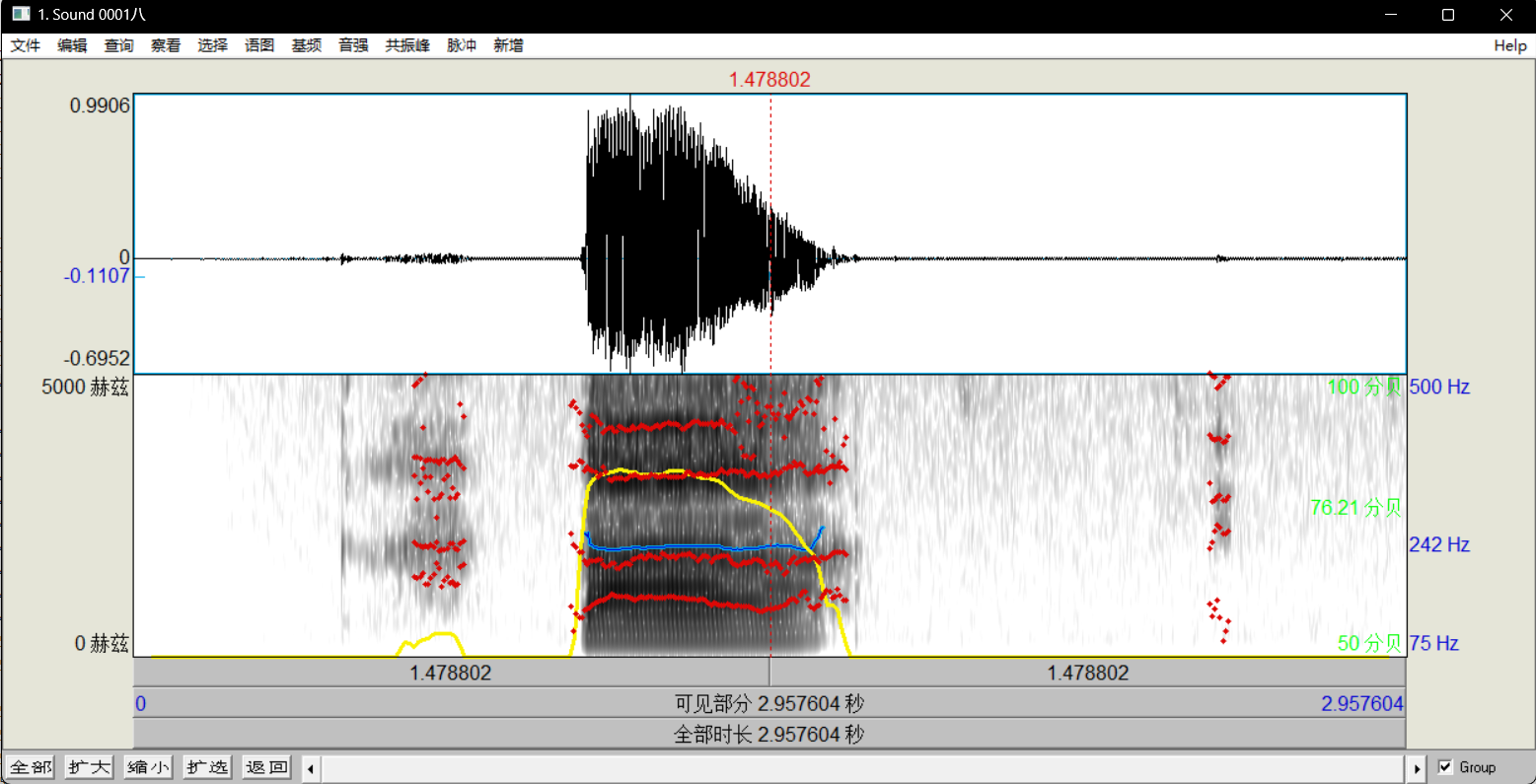
- 在语图中,蓝色曲线即为基频曲线,红色曲线是共振峰曲线,黄色曲线是音强曲线。
- 在本次实验中,为了减少视觉干扰,我们将音强曲线和共振峰曲线隐藏,点击
音强→显示音强,则可以切换音强曲线的显示状态。同理,进行共振峰曲线的隐藏操作。
选取声调段
我们已经知道了基频曲线在praat中的表现,那么是不是整个基频曲线我们都需要呢?NO。
声调的起点从韵腹(元音)的起点算起。在语图上从元音的第二个脉冲算起(Lisker oOias n 19o3:416 ;Baken 1987:376),见图2。
图2中箭头指向下面宽带图中第二个声门脉冲直条,即上面声波图中第二个周期。声调起点可以从此处开始算起。第一个明显的声门脉冲在测量声调时常被忽略,因为此时元音的舌位还未到位,振幅也不够大,人耳听不到。而且,此时声母辅音对声调的影响非常大。当然,并不是绝对不能从第一个脉冲直条处算起,重要的是测量标准前后保持一致。
确定终点有统一的标准,还有根据调形不同而定的辅助标准。统一的标准包括:
(1)声波图中振幅显著下降。
(2)看宽带图中第二共振峰是否还清晰,如果共振峰结构已经模糊,可以认为是声调的终点。——朱晓农《语音学》
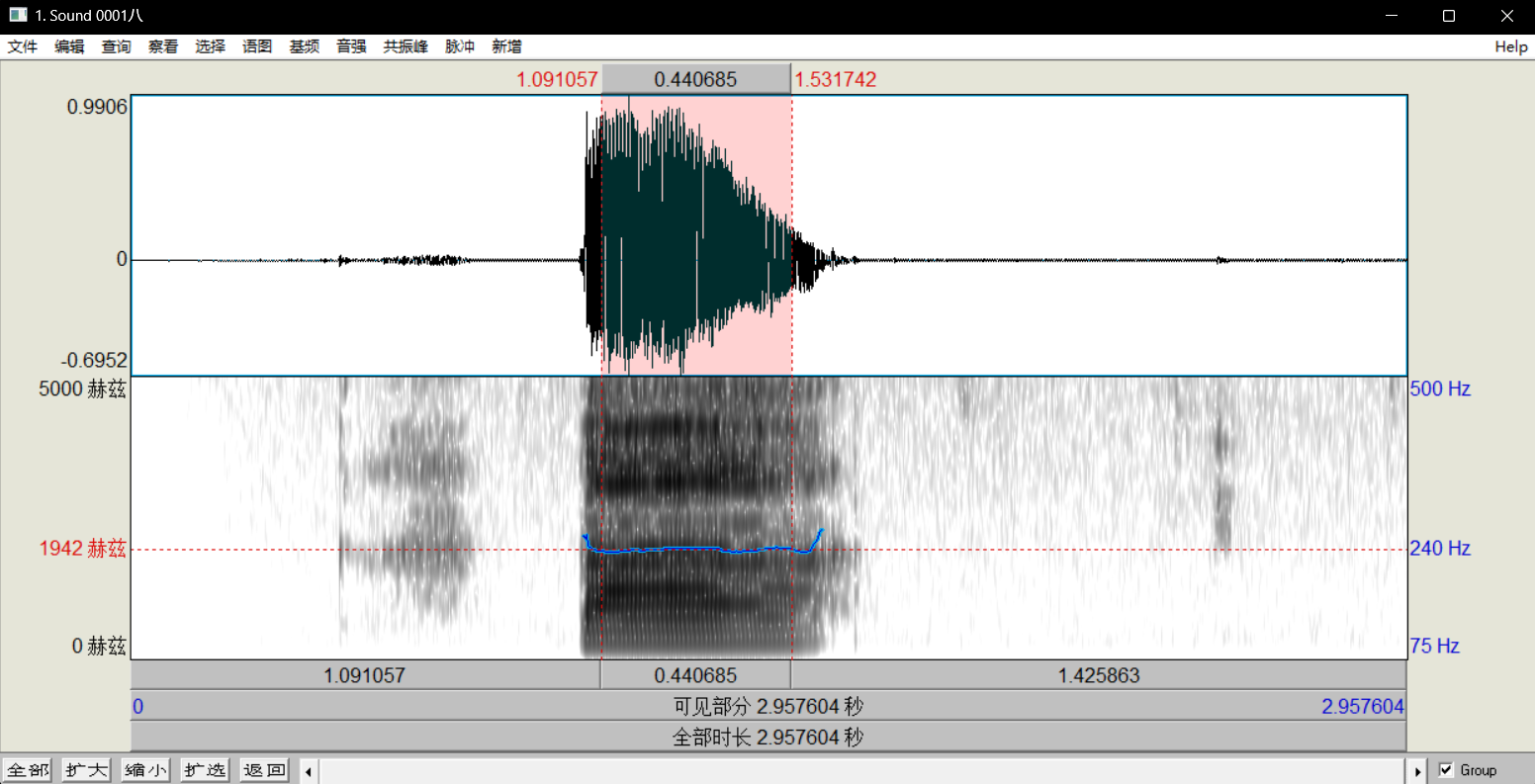
- 试听音频:如果想试听整个文件中的某个音频片段,从音频片段的起点处点击鼠标左键,按住不动并向右拖至音频片段的终点。点击下方的时长,即可播放该片段声音。
测量基频(Hz)
-
选取声调段后,点击
基频→Bei 测量基频: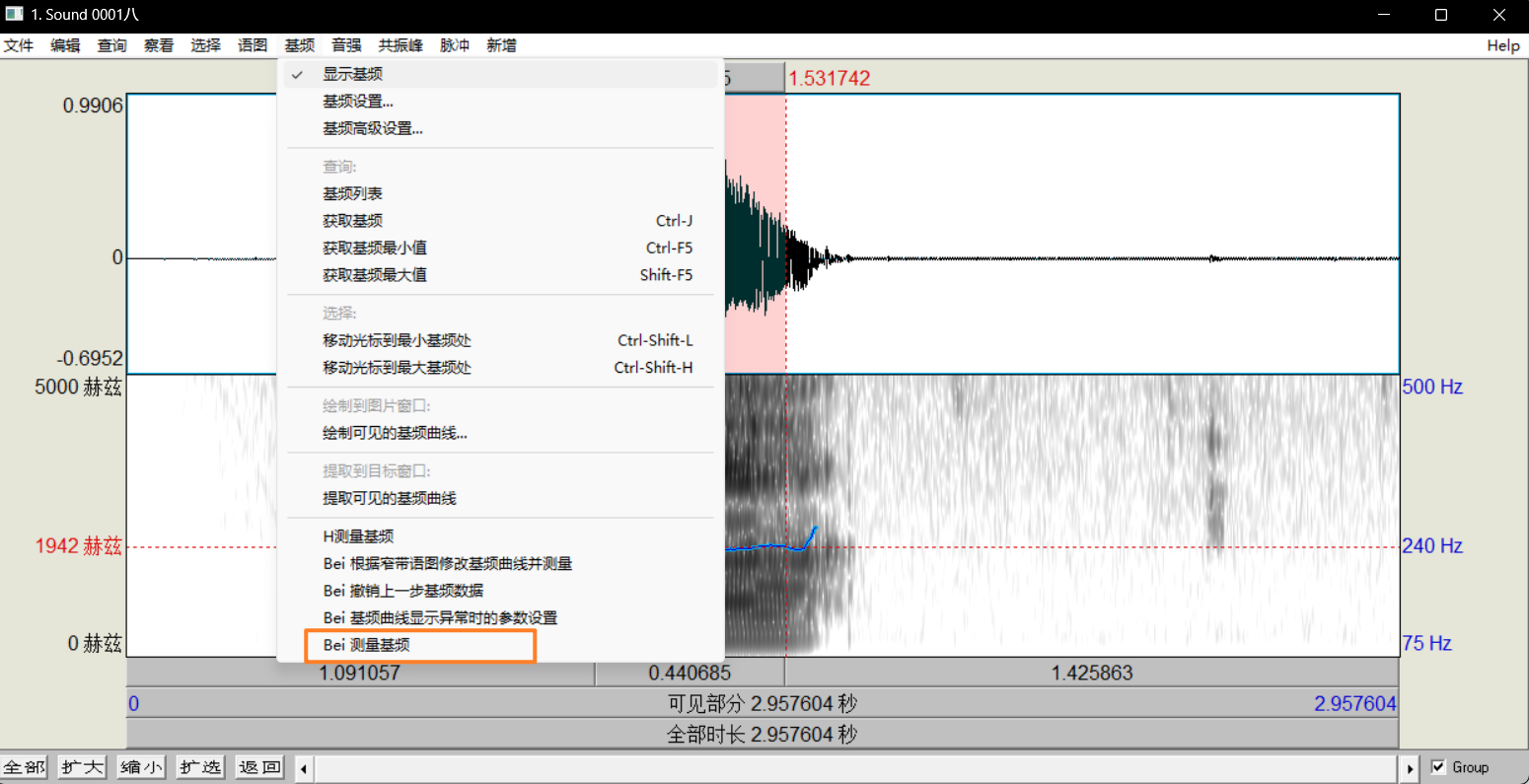
-
在弹出框里输入调类名称,点击继续。
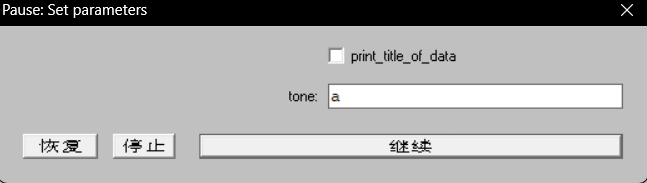
-
弹出数据框:

注意:该弹出框不需要进行编辑或保存操作,文件已经自动保存在文件安装目录下的 data 文件夹中的 tone.txt 文件。因该文件是自动生成及追加写入,建议每次完成一次声调实验后另存为必要的命名和位置后对该文件进行清除,否则 tone.txt 文件里的实验数据会和之前的相混
-
重复上述步骤,直至所调查语言的所有字调基频数据均已收集。此时相关数据也已经自动保存至tone.txt。
基频归一化
-
在 praat 软件的主界面,点击左上角
praat→声调→Bei 声调统计与画图 (相对时长)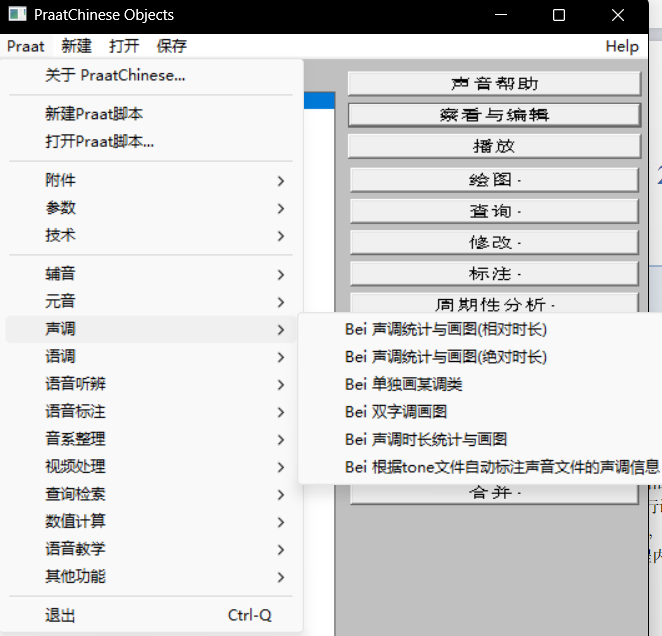
2.弹出框中可以设置一些属性: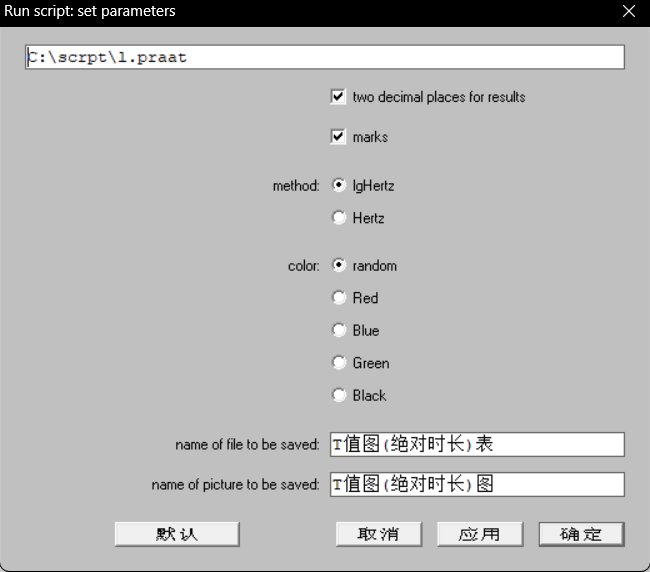
marks:刻度虚线two decimal places for results:结果保留两位小数。method:选择赫兹的对数值或直接使用赫兹值,两者差异不大。一般默认使用lg值。color:五度调值图里各调类的画线颜色。name:对生成的表和图进行命名,并自动保存在data文件夹下。
- 在弹出框里打开基频文件(tone.txt),即可生成图表。
图表呈现
-
在上一步打开基频文件后,会弹出两个窗口(见下图),左图描述基频极值,右图则是声调格局图。
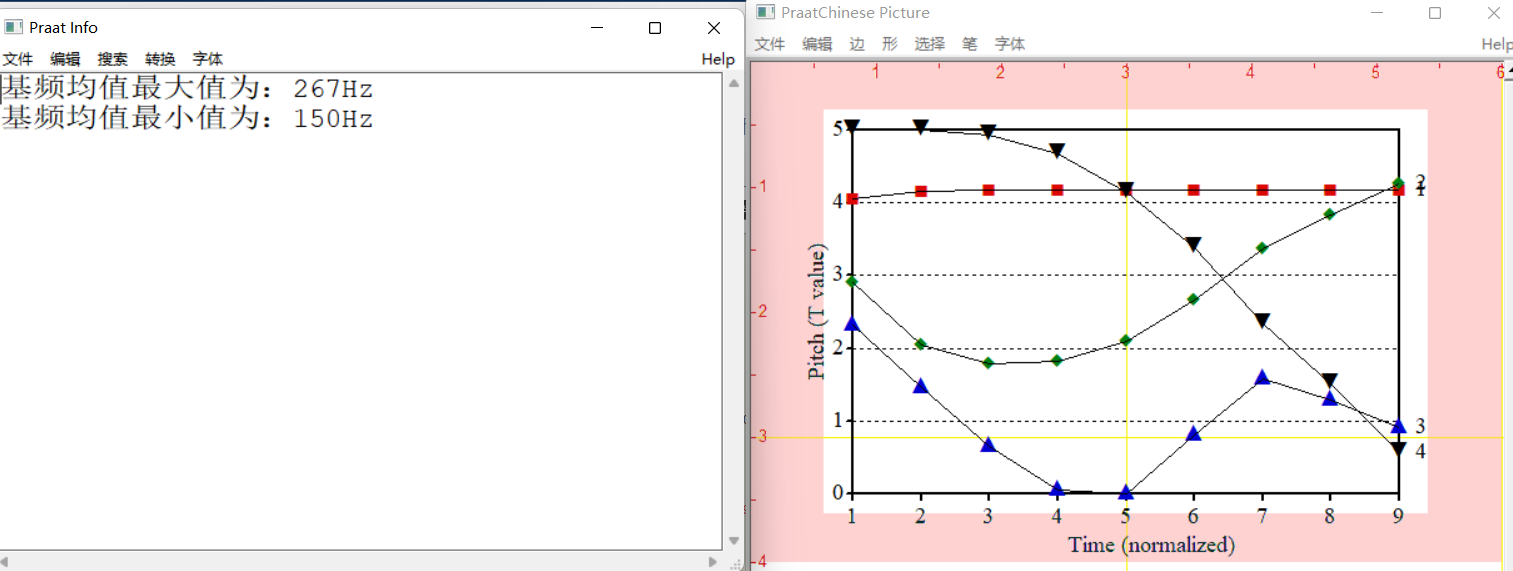
-
同时,与前文中自动生成tone.txt类似,此时在软件目录下的data文件夹里也出现了T值表和T值图,可自行粘贴进论文里。
单独画某调类
如果我们不想呈现全部的调类,想单独绘制某一个调类或几个调类应该怎么办呢?
-
点击
打开→从文件读入…,打开你的T值表(注意:不是打开原始的tone文件,而是打开上一步部分生成的T值表)。导入T值表后,点击该文件选中。
-
点击
praat→声调→Bei 单独画某调类。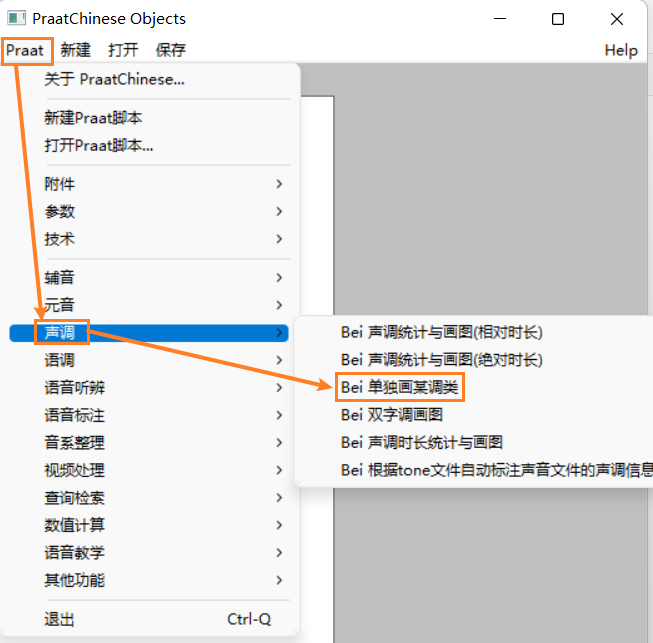
-
在弹出框中,
marks和color参数前文已经介绍。并且此处也提醒用户:读入T值表后再运行脚本。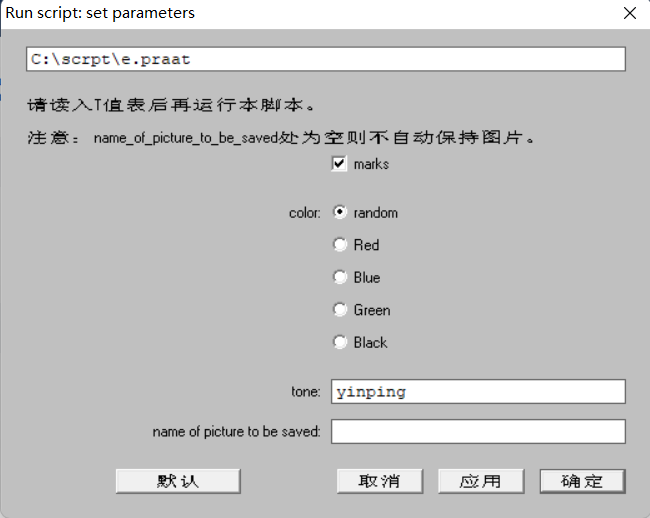
tone:要绘制的调类,与T值表里的调类名称一致。name of picture to be saved:保存的图片名称,为空则不自动保存。
设定好参数后,点击应用或确定,应用运行后不关闭该窗口,方便再画其他调类;确定则运行后直接关闭该窗口。
-
弹出绘图框,可以发现我们已经绘制了一个调类。
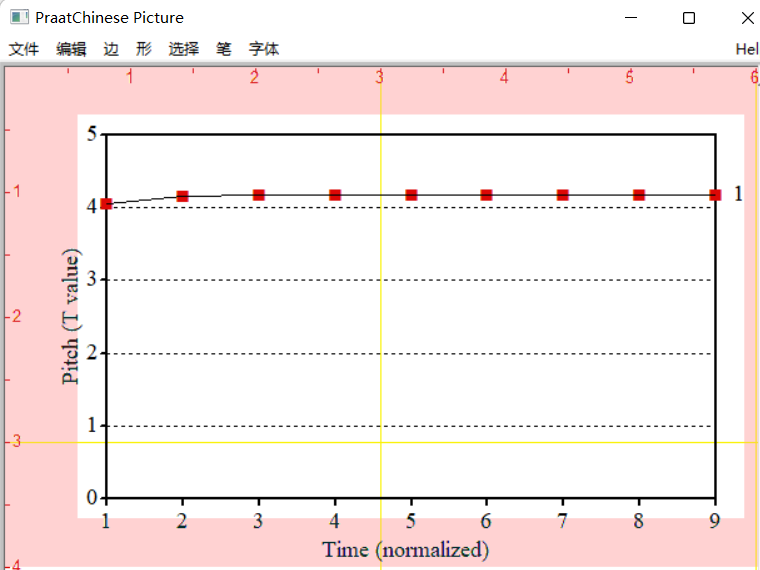
如果你在上一步设定了name of picture to be saved,则在data文件夹里也生成了对应的图片文件。
注意:如果之前的绘图没有关闭或者擦除(比如在前面绘制了一个所有调类的格局图),则会追加绘制。你需要在此之前擦除无用的内容。
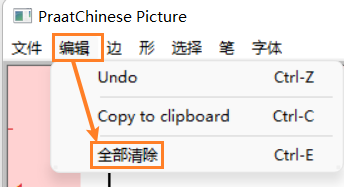
-
如果还要在此基础上,再画一个或多个调类,则重复以上步骤。图片同样自动存储在data文件夹内。
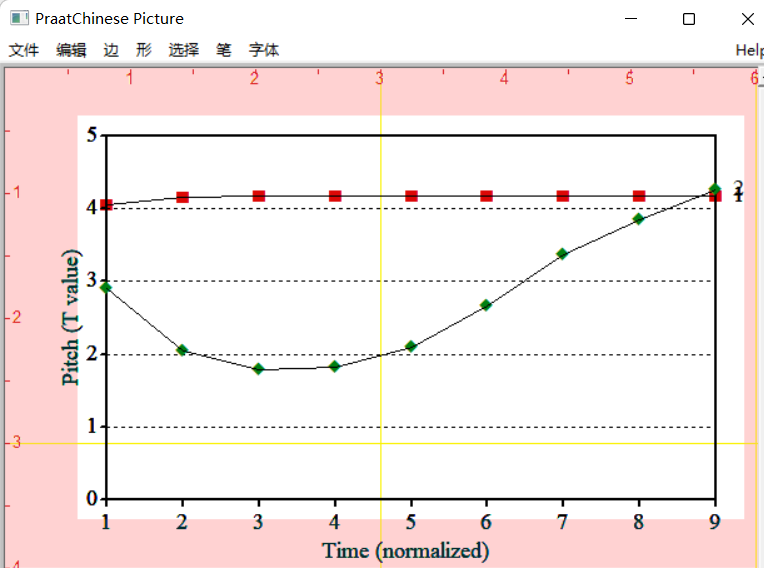
操作步骤-双字调分析
录入/读取音频
-
打开 praat 软件,点击
打开→从文件读入…,将声调文件读入(可一次读入多个文件)。这一步与单字调分析完全相同。
测量基频(Hz)
-
选取声调段时,仍旧是一个字一个字的提取基频,如“开车”这个词,先选取“开”的基频段,点击
基频→Bei 测量基频。: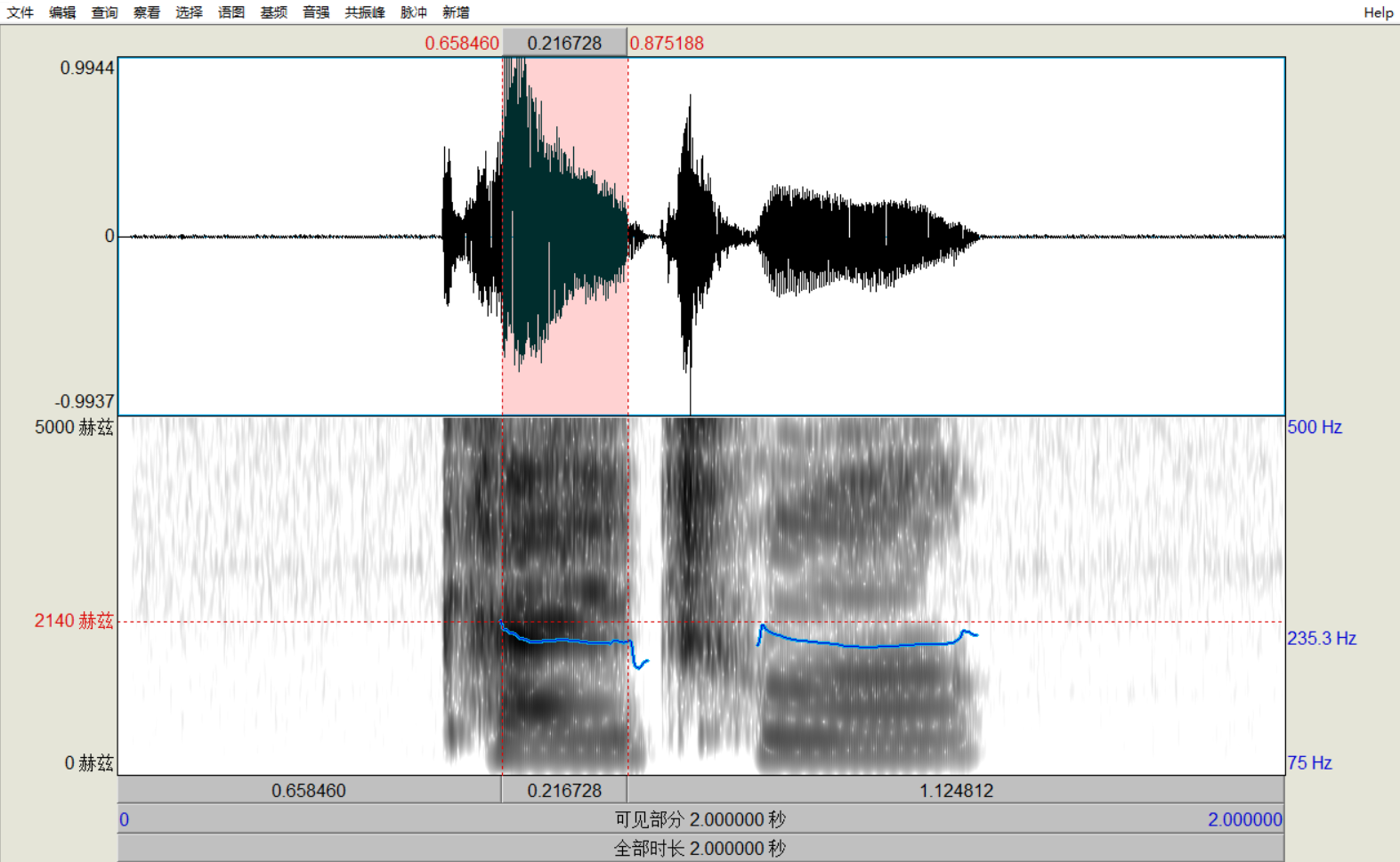
注意:在弹出框里输入调类名称,此处调类名称要注意命名,并且记清对应关系,因为后文画出某一个双字调之时需要此时的取名,“开车”是一个阴平配阴平的词,则“开”可以命名为“11-1”,表示阴平配阴平的第一个字。同理,“车”命名为“11-2”。命名没有强制性,表义清晰不混淆即可。不要使用中文,有时会出现卡死现象。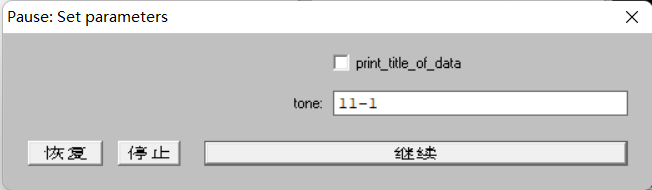
-
重复操作步骤,直至采集所有的双字调组配情况。在data文件夹下仍旧生成一个tone.txt文件夹。
基频归一化
-
在 praat 软件的主界面,点击左上角
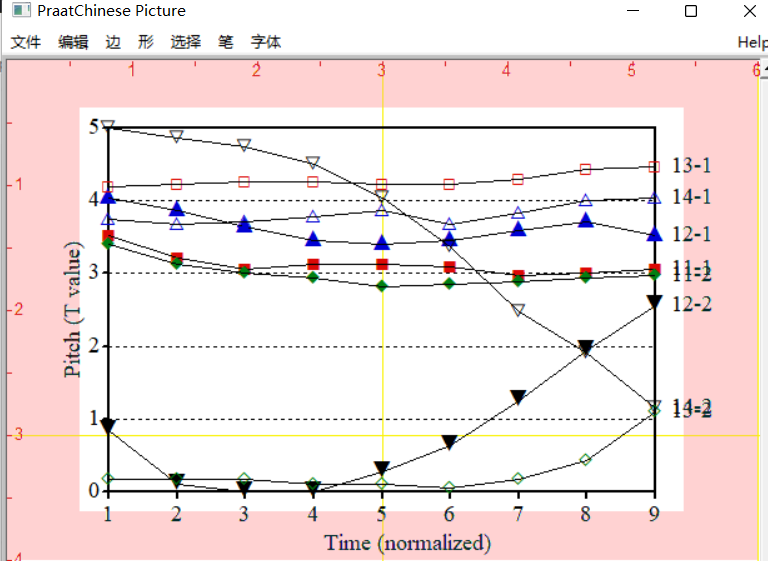
praat→声调→Bei 声调统计与画图 (相对时长) -
读取tone文件,与单字调分析步骤一致,会生成T值表和T值图。T值图并非我们想要的图,因为双字调线条庞杂,生成的图让人眼花缭乱(见下图),这一步骤的目的是为了得到T值表,为了后面依据研究目的单独画某些字调。
双字调画图
-
读入T值表(与单字调分析步骤相同),点击
praat→声调→Bei双字调画图
-
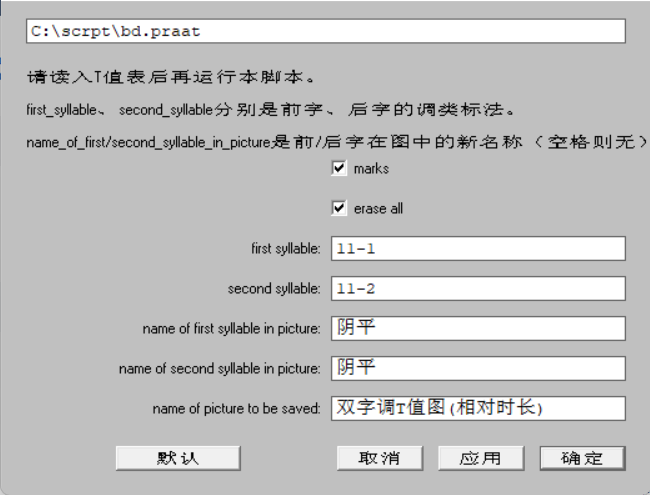
在弹出框里输出参数。参数已经自带说明,见下图。
双字调图呈现如下,同时在data文件夹下也生成了相应的矢量图。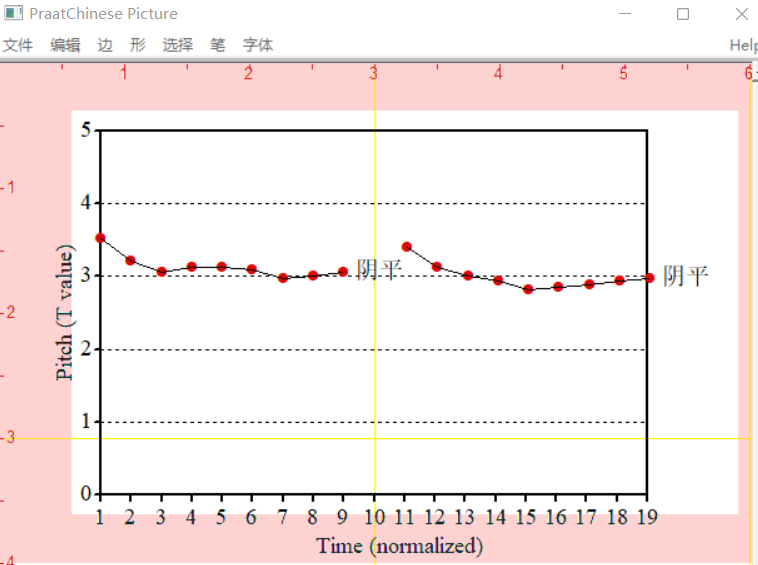
.png)
余论
异常值处理
在统计分析中,异常值是指与数据集中的大多数观测值显著不同的观测值。在常规数据中,可以采用很多统计方法去除异常值,如根据Z-Score的阈值、标准差的阈值、箱线图等方法进行筛除。可以采用某些软件工具进行筛除,如Excel、SPSS、Python、R等。一些脚本里也内置了筛除方法,详见本文末扩展阅读里的脚本网站。本文不再作扩展。
但是对于声调数据,在时间充足的情况,仍建议根据原始基频图人工筛选每条数据。因为极端值有可能是错误数据(绝大多数情况下),也有可能存在某些新现象。不具备普遍性,但或许有个案研究的价值。
扩展阅读
- 贝先明, 2012. 普通话的声调格局和元音格局[J]. 武陵学刊, 37(04): 131-136.
- 石锋, 冉启斌, 王萍, 2010. 论语音格局[J]. 南开语言学刊(01): 1-14+185.
- 石锋, 时秀娟, 2007. 语音样品的选取和实验数据的分析[J]. 语言科学(02): 23-33.
- 朱晓农, 2004. 基频归一化——如何处理声调的随机差异?[J]. 语言科学(02): 3-19.
- 石锋, 2006. 实验音系学与汉语语音分析[J]. 南开语言学刊(02): 10-25+164.
- Praat 脚本程序 | 语音与言语科学重点实验室
如果您想直接浏览本系列文章,可点击文末标签“实验语音学常用软件入门”。
- 0
- 0
-
分享