.png)
实验语音学常用软件入门•Praat声调范畴感知实验
编辑本文“操作步骤”部分内容基于软件“Praat汉化修改版4.5”(Paul Boersma & David weenink 开发,贝先明和向柠 修改)相关课程的教学内容,其余内容为笔者构思、撰写与引用。本文仅用于个人学习交流目的,不可用于商业用途。如有任何侵权行为,或本文中的任何内容侵犯了原软件作者的版权,请在第一时间告知作者,我将立即采取措施解决。本文采用CC BY-NC-SA 4.0许可协议。你可自由分享、演绎,但需署名、非商业使用,并以相同许可协议分享演绎作品。
此为使用Praat脚本实现的一个较为基础的感知实验,若需使用更规范和精确的软件,请移步《基于Psychopy的语音感知实验操作示例》
理论基础
范畴化感知与连续型感知
范畴化感知(Categorical Perception)和连续型感知(Continuous Perception)是心理学和认知科学领域中两种不同的感知现象。
- 范畴化感知:
- 范畴化感知是指对于某一属性或特征的感知在某个范围内被归为同一类别,而在超出该范围时则被视为不同类别的现象。这种感知方式导致了对于差异的敏感性在某个范围内降低。
- 一个经典的例子是语音范畴化感知。在语音学中,人类倾向于将声音划分为不同的语音类别,而对于同一类别内的差异则表现出相对不敏感的特点。这就是说,当两个声音在同一语音类别内时,即使它们之间的差异很小,人们也可能无法明显地感知到这种差异。
- 连续型感知:
- 连续型感知是指感知过程中对于刺激差异的连续和均匀的感知。在这种感知中,人们更容易区分刺激之间的微小差异,而不会在某个阈值范围内将它们划分为不同的类别。
- 视觉上的亮度感知可以被认为是一种连续型感知。人们可以感知到光的亮度的微小变化,而不会将它们划分为不同的亮度类别,除非差异足够大。
范畴化感知和连续型感知代表了两种不同的感知机制,分别在某个范围内更强调类别划分,而在另一方面更注重对于刺激差异的连续感知。
声调范畴感知
声调范畴化感知,是指语音刺激的连续统被感知为离散的、数量有限的范畴。在两个声调之间,可以有许多变体,但它们只分别能被感知为两个声调,在同一个声调的感知范畴内,无论变化有多大,感知的结果是一样的,因它们同属一个范畴,在不同的声调感知范畴中,两个样本不论差别有多小,仍被感知为不同的声调。
声调感知的实验方法借鉴心理学实验模式,较常用的是辨认实验和区分实验。
- 辨认试验:要求被试对被呈现的声音刺激做出是A还是B的判断。
- 区分实验:要求被试对被呈现的声音刺激做出是相同还是不同的判断。
在具体实验中,每次给出一个样本,让听辨者选择它是两个选项中的哪一个,两者必选其一。区分实验阶段常用的有二项迫选法,即每次随机呈现一组刺激,包含两个刺激声,被试必须回答这两个刺激声相同或不同。下图出示了理想的辨别实验结果:辨认实验中,范畴边界处,斜率变得很陡峭。区分实验中,被试对于同属一个范畴的刺激区分正确率在50%,不能很好辨别,而对于两个范畴界线两边的刺激,听辨者的区分正确率突然变得很高。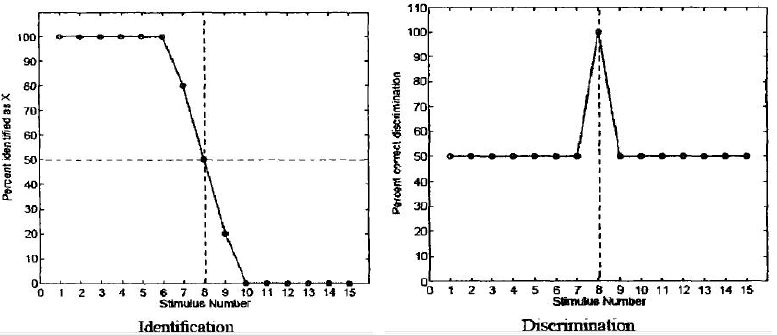
实验设计
实验设计原则
- 在实验条件允许范围里优先选择接近实际语言交际的方案。
- 测试采用真词成对作为刺激材料
- 单一变项原则。
选择实验字/词
对于如何选取声调范畴实验的实验字,不同学者的选择方法有所不同,有采用负载句,双字组词对,单音词等方式,在此不作过多讨论,不同的选取方法的特点可参看相关论文。
本教程考虑到操作步骤的简明性,以单字为例进行操作。
尽量选用常用字,保证具备初等文化水平的人就能认出,如选用“号”而不选用“皓”。
尽量选用口语字。如选用“盐”而不选用“裔”。
尽量选用共振峰模式比较单一,字音在各派发音中大体保持一致,不致引起听感混乱的字。
尽量选用能单说单用的单音词”。首选单音节动词、数词、量词和代词,在没有好的候选字可供选择的情况下,再考虑酌情选用单音节名词、形容词等。如选用“盐”而不选用“怡”。
剔除存在异读需要额外解释的词。比如用“亿”而不用“咽”,因为“咽”有阴平阴去两读。
——高云峰. 声调感知研究[D]. 上海师范大学, 2004.
合成刺激音
在合成刺激音之前,需要做出发音人的声调格局,以确定其调域。刺激音合成时,调域跨度不能小于发音人的调域。
- 对角测试法
- 设定人们的声调听觉有一个空间,用对角线线把这个空间分成两半。每次利用其中的一半,可以有前上、后上、前下、后下四种半空间。那么,上声-去声听辨利用了前下半空间;上声-阳平听辨利用了后下半空间。上声的整体听感空间包括:上声-去声起点处的分界、上声-阳平终点处的分界、以及上声-平两个平调之间的整体分界。
- 通过对角测试法,我们可以确定各个调的起点和终点的上下限,从而确定各个调类的听感空间。
- 平行测试法
- 按照声调的机同调型做出平行线的连续统,这样得出的是声调的整体边界,而不是起点或终点的边界。平行测试法适用两个调只有调阶上的区别时。
实验被试
- 根据不同的实验要求,被试的选择标准也不尽相同。
- 普通话声调实验的被试一般选30人左右,男女平均,年龄相仿。北方方言背景,普通话标准。身体健康,右利手,无阅读、听力障碍。
- 实验也可以选择不同方言或者语言背景的被试,比如,可以比较汉语不同方言区的人对声调感知有何不同,又如可以选择外国留学生汉语声调习得的感知情况等
实验软件
-
Praat汉化修改版4.5(Paul Boersma & David weenink)开发,贝先明和向柠(2020)修改)
-
Praat脚本:声调连续统刺激音生成.scp(作者:熊子瑜),下载地址
注意:感知实验一般使用E-prime、PsychoPy等软件进行,主要收集RESP(按键反应)与RT(反应时间)数据。Praat汉化修改版也内置了脚本用以收集这两种数据,为减轻操作难度,本文以Praat汉化修改版展开操作。如有余力,可学习E-prime的相关操作。
操作步骤
我们以普通话阴平-阳平的范畴感知为例,讲解主要的操作步骤,某些参数及操作上的细节可参考文末拓展阅读,在操作过程中不作较细的讨论和叙述。该演示这并非一个完善且严谨的实验,只是以此讲解主要的操作步骤。
合成刺激音
计算调域范围
通过Praat软件测得调域边界,方法在此不再赘述。
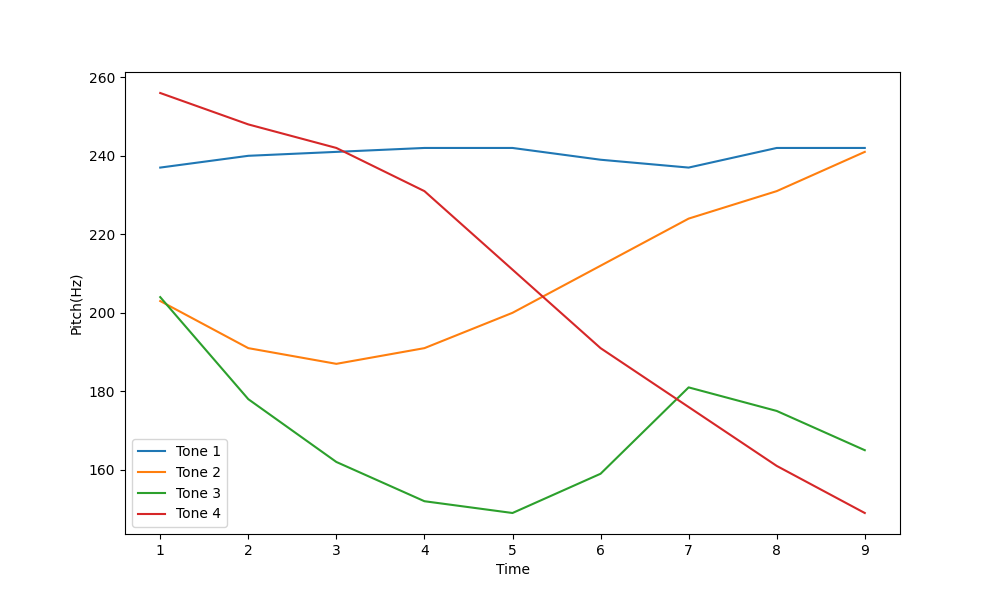 分析得阴平的基频范围: (237, 242),阳平的基频范围: (187, 241)
分析得阴平的基频范围: (237, 242),阳平的基频范围: (187, 241)
1.点击 Praat→Open Praat script…,打开 声调连续统刺激音生成.scp
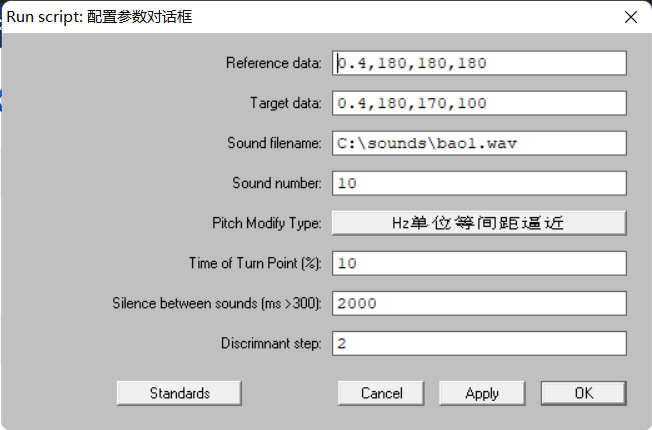
参数讲解:
Reference_data:第一个数据为基频段时长数据,为0时则表示不做时长处理,直接采用原始声音的基频段时长;如果大于0,则将第一个生成的刺激音的基频段时长调整为该值(单位为秒);后续为N个音高点的基频数据,单位为Hz。Target_data:第一个数据为基频段时长数据,为0时则表示不做时长处理,直接采用原始声音的基频段时长;如果大于0,则将最后一个生成的刺激音的基频段时长调整为该值(单位为秒);后续为N个音高点的基频数据,单位为Hz。
注意:如果设定基频段时长值,则在上面两个参数中都应该进行设置,否则将其均赋值为0;Sound_filename:声音文件名,即要修改的声音文件,脚本程序以该声音文件为基准去合成生成相应的刺激音;该声音文件的音高数据应接近于reference_data中所给定的音高数据,有利于提高合成声音的质量。Sound_number:要生成的连续统刺激音数量。
注意:为了精确控制相邻字音的间隔空白段时长(脚本程序会根据用户输入的值来确定,应至少大于300毫秒),请将输入的声音首尾空白段完全删除,此脚本程序会自动插入150毫秒的首尾空白段;Silence_between_sounds:拼接两个刺激音时中间的空白段时长。Discrimnant_step:区分实验中两个目标刺激音的间隔步长,如1和3相配、2和4相配则步长为2,默认为2Pitch_Modify_Type: 音高逼近的改变方式,可以选择按照Hz标度或者St(半音)标度。Time_of_Turn_Point:如果有拐点的话,设定拐点在基频段中的位置,按百分比方式设置,如20,则为0.2,即在基频段时长的20%处设置为拐点位置;只有当音高数据设置为3个值(起点、拐点、末点)时,中间的那个数据默认为拐点数据,此时设置拐点位置才有意义,如果音高数据少于或多余3个值,则不考虑拐点信息。
辨认/区分试验
制作内容提示文件
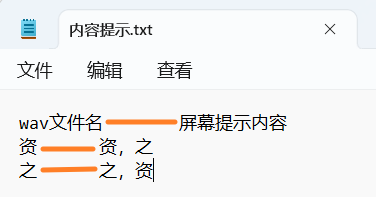
区分实验和辨认实验均依赖“内容提示.txt”文件,两种实验的文件格式大致相同,内容有所不同,示例如下。
- 区分实验示例
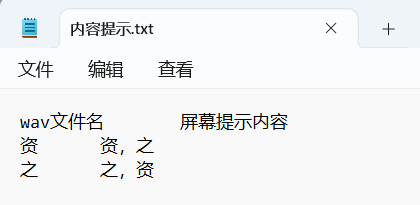
内容格式浅显易懂,但需注意,列与列之间是由Tab空格连接的(见下图橙色线),在输入的过程中可以复制前面已有的Tab,而不要键入普通空格键。或使用Excel编写之后转换为txt格式。
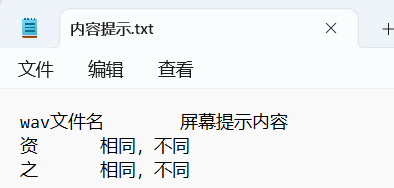
- 辨认实验示例
内容基本相同,只是将前文屏幕提示内容改为“相同,不同”。
- 该文件命名必须为“内容提示”,且后缀为.txt文件。
- 内容提示.txt的第一行标题是“wav文件名 屏幕提示内容”。(Tab空格连接)
- 列与列的间隔符均为Tab空格。
- 辨认实验中,提示内容.txt中的词对必须和实际播放语音文件的数量和顺序一致。
- 内容提示.txt和相关的wav文件均位于相同的文件夹。
听辨实验
- 点击
Praat>语音听辨>Bei听辨实验数据收集。
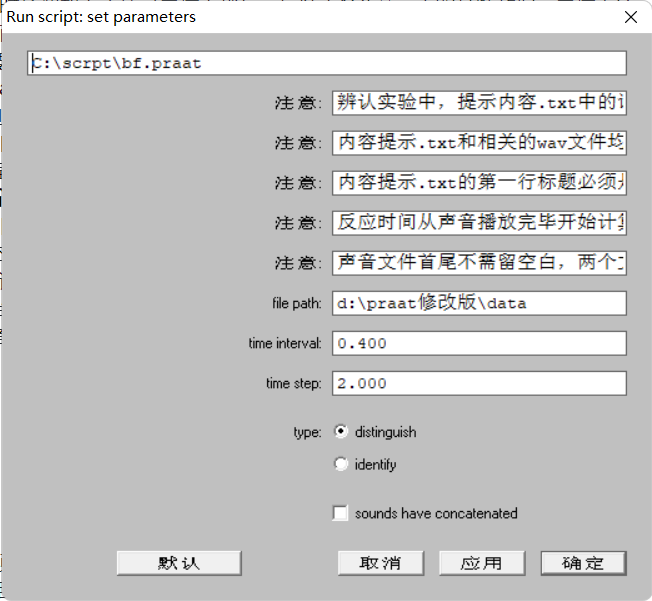
参数解释:file path:声音文件所在的路径。time interval:区分实验中,两个声音间隔多少秒。time step:听完一个后,多少秒进入下一个。type:区分实验还是辨认实验。sound have concatenated:两个声音是否事先合并了。
- 被试只能按F和J键,实验前记得将输入法切换到英文状态。如果点击鼠标或者按其他键,均会退出实验。所以,实验前务必将此情况告诉被试。或者另做实验前的训练。
- 实验结果存放在data的“听觉实验.txt”中
- 反应时间从声音播放完毕开始计算,如果测量某个反映时间为负值(如-0.050秒),说明本次按键在声音尚未播放完毕的情况(如提前了-0.050秒)按下的。
- 声音文件首尾不需留空白,两个文件中间的停顿通过
time_step设定。 - 辨认试验必须勾选
sounds have concatented。
拓展阅读
高云峰. 声调感知研究[D]. 上海师范大学, 2004.
荣蓉. 汉语普通话声调的听感格局[D]. 南开大学, 2014.
微信公众号:实验语音学与praat软件
微信公众号:语音学堂
- 0
- 0
-
分享